0x00 序
今天在网上看到平底锅blog上Josh Grunzweig发表了一系列关于利用IDAPython分析malware的教程。感觉内容非常不错,于是翻译成中文与大家一起分享。原文地址:
Part1: http://researchcenter.paloaltonetworks.com/2015/12/using-idapython-to-make-your-life-easier-part-1/
Part2: http://researchcenter.paloaltonetworks.com/2015/12/using-idapython-to-make-your-life-easier-part-2/
0x01 背景
作为一名malware逆向工程师,我的日常活动就是使用IDA Pro。这并不奇怪,因为IDA Pro可以说是行业标配(尽管它的替代品,如radare2和hopper也越来越受欢迎)。IDA其中一个非常强大的功能就是可以使用Python脚本(又被称为IDAPython)。用户可以通过IDAPython调用大量的IDA API。当然,用户还可以通过使用IDAPython获取到脚本语言提供的各种功能。
不幸的是,只有少量的关于IDAPython的资料,仅有的一些资料如下:
- Chris Eagle的The IDA Pro Book
- Alex Hanel的The Beginner’s Guide to IDAPython
- Magic Lantern 的IDAPython Wiki
0x02 利用IDAPython解决字符串加密问题
为了能提供更多的教程给分析师,我准备写一篇带例子的分析文章供大家学习。在本系列的第一部分,我将教大家编写一个脚本用来解决一个malware样本的多处字符串混淆问题。
在逆向分析一个病毒样本的时候,我遇到了这样一个函数:
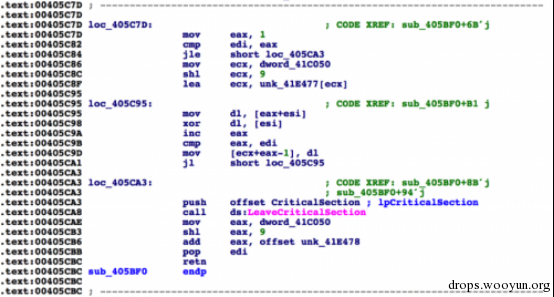 图片1 字符串解密函数
图片1 字符串解密函数
根据以往的经验,我怀疑这个函数是用来进行解密的。关于这个函数大量的引用证实了我的猜想。
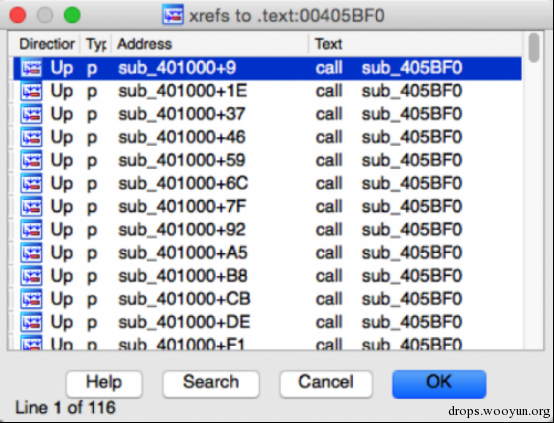 图2 大量的对可疑函数的引用
图2 大量的对可疑函数的引用
在图2中,我们可以看到有116处对这个函数的引用。每当这个函数被调用时,都有一段数据作为参数通过ESI寄存器提供给这个函数。
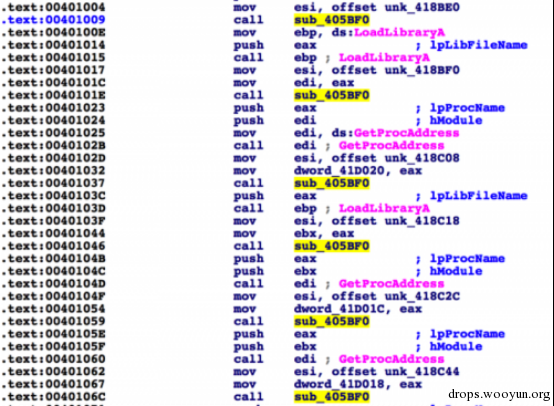 图3可疑的函数 (405BF0) 被调用的实例
图3可疑的函数 (405BF0) 被调用的实例
在这个时候,我已经非常肯定这个函数是malware用来在运行时进行字符串解密的函数了。当我们面临这种情况时,我们一般有如下几种选择:
- 我可以手动解密然后重命名这些字符串。
- 我可以动态调试这个样本然后重命名遇到的字符串
- 我可以写一个脚本用来解密并且重命名这些字符串
如果malware只解密了很少的几个字符串的话,我会选择第一种或者第二种方法。但是,根据之前确认的,这个函数被调用了116次,所以采用IDAPython脚本来解决问题会更靠谱一些。
解决字符串混淆问题的第一步是确认和重写解密函数。幸运的是,这个解密函数非常的简单。这个函数只是把数据的第一个字符当做XOR算法的key用来解密剩余的数据。
E4 91 96 88 89 8B 8A CA 80 88 88
在上面这个例子中,我们把E4作为key来异或剩余的数据。最后的结果是”urlmon.dll”。在Python中,我们可以把这个解密函数重写为:
#!python
def decrypt(data):
length = len(data)
c = 1
o = ""
while c < length:
o += chr(ord(data[0]) ^ ord(data[c][/c]))
c += 1
return o
可以看到,我们的测试脚本可以得到我们所期望的结果:
#!bash
>>> from binascii import *
>>> d = unhexlify("E4 91 96 88 89 8B 8A CA 80 88 88".replace(" ",''))
>>> decrypt(d)
'urlmon.dll'
我们要做的下一步工作就是确认哪些代码引用了这个解密函数,并且提取作为参数的数据。获取到函数的引用非常的简单,只需要使用XrefsTo()这个API函数就能达到我们的目的。在这个脚本中,我将会在脚本中硬编码这个地址。作为测试,我先将这些地址用16进制打印出来:
#!python
for addr in XrefsTo(0x00405BF0, flags=0):
print hex(addr.frm)
Result:
0x401009L
0x40101eL
0x401037L
0x401046L
0x401059L
0x40106cL
0x40107fL
<truncated>
获取到这些交叉引用的参数并且提取这些原始数据需要一些技巧,但绝非很难。第一件我们想要做的事是获取”mov esi, offset unk_??”指令中的偏移地址,因为这个指令会把参数传递给解密函数。为了做到这点,我们需要找到调用解密函数指令的前一个指令。找到这个指令后,我们可以使用GetOperandValue() 这个指令得到这个偏移地址的值。如下面的代码所示:
#!python
def find_function_arg(addr):
while True:
addr = idc.PrevHead(addr)
if GetMnem(addr) == "mov" and "esi" in GetOpnd(addr, 0):
print “We found it at 0x%x” % GetOperandValue(addr, 1)
break
Example Results:
Python>find_function_arg(0x00401009)
We found it at 0x418be0
现在我们只需要将字符串从那个偏移地址中提取出来即可。正常来说我们会使用GetString()这个API函数,但是在这个问题中这些字符串都是原始的二进制数据,因此使用这个API可能不太合适。解决方案是我们自己编写一个函数,然后一个字符一个字符的读取数据直到碰到空的终止符为止。代码如下:
#!python
def get_string(addr):
out = ""
while True:
if Byte(addr) != 0:
out += chr(Byte(addr))
else:
break
addr += 1
return out
最后,我们将所有的代码放在一起:
#!python
def find_function_arg(addr):
while True:
addr = idc.PrevHead(addr)
if GetMnem(addr) == "mov" and "esi" in GetOpnd(addr, 0):
return GetOperandValue(addr, 1)
return ""
def get_string(addr):
out = ""
while True:
if Byte(addr) != 0:
out += chr(Byte(addr))
else:
break
addr += 1
return out
def decrypt(data):
length = len(data)
c = 1
o = ""
while c < length:
o += chr(ord(data[0]) ^ ord(data[c][/c]))
c += 1
return o
print "[*] Attempting to decrypt strings in malware"
for x in XrefsTo(0x00405BF0, flags=0):
ref = find_function_arg(x.frm)
string = get_string(ref)
dec = decrypt(string)
print "Ref Addr: 0x%x | Decrypted: %s" % (x.frm, dec)
Results:
[*] Attempting to decrypt strings in malware
Ref Addr: 0x401009 | Decrypted: urlmon.dll
Ref Addr: 0x40101e | Decrypted: URLDownloadToFileA
Ref Addr: 0x401037 | Decrypted: wininet.dll
Ref Addr: 0x401046 | Decrypted: InternetOpenA
Ref Addr: 0x401059 | Decrypted: InternetOpenUrlA
Ref Addr: 0x40106c | Decrypted: InternetReadFile
<truncated>
我们可以看到所有解密后的字符串。如果我们可以进一步给字符串的引用地址和加密数据提供解密后的字符串作为注释就更完美了。想要做到这一点,我们需要MakeComm()这个API函数。增加这样两行代码就会给程序加入必要的注释:
#!python
MakeComm(x.frm, dec)
MakeComm(ref, dec)
增加了这一步后,我们能够非常清晰的看到交叉引用的数据。如下图所示,我们可以很轻松的分辨出哪些字符串被引用了:
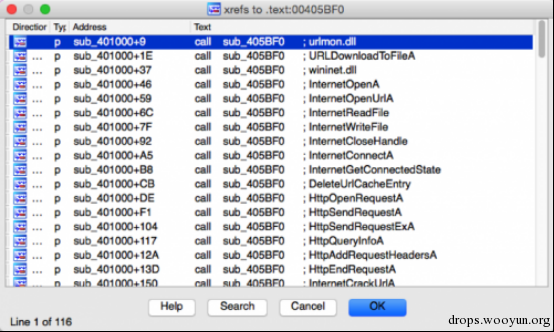 图4 运行完脚本后的字符串交叉引用界面
图4 运行完脚本后的字符串交叉引用界面
除此之外,我们在反汇编代码中也能看到这些解密后的字符串作为注释:
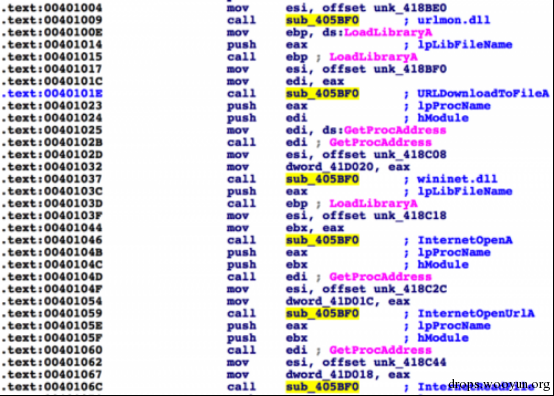 图5 运行完脚本后的反汇编代码
图5 运行完脚本后的反汇编代码
0x03 利用IDAPython解决函数/库调用的哈希混淆问题
在反编译中我们经常会见到shellcode和malware使用哈希算法来混淆加载的函数或者库。比如逆向工程师们经常会在shellcode中看到混淆后的函数名。总的来说,整个过程是很简单的。代码在运行时会先加载knerel32.dll。然后,它会用这个加载的镜像去识别并存储LoadLibraryA函数,这函数是用来加载更多的库和函数的。这种特定的技术一般采用某种哈希算法来识别函数的。最常用的哈希算法一般是CRC32,当然,其他的一些变种算法,如ROR13,也是非常常见的。
比如说,当我逆向一个malware的某一部分内容的时候,我看到了如下的代码:
 图片6 malware使用CRC32哈希算法来动态的加载函数
图片6 malware使用CRC32哈希算法来动态的加载函数
因为0xEDB88320这个常数是CRC32算法的常用参数。所以我们可以判断出这个例子使用了CRC32哈希算法。
 图片7 确认CRC32算法
图片7 确认CRC32算法
通过图7我们可以确定这个算法是CRC32算法。现在,算法和函数已经确定了。我们可以通过交叉引用(ida中按x)的数量来确定这个函数被被调用了多少次。可以看到这个函数一共被调用了190次。显然,手动的解密并重命名这些哈希值并不是我们想要的。因此,我们可以使用IDAPython来帮我们解决。
第一步实际上并不需要IDAPython,但是它用到了Python。为了验证哪个哈希值对应哪个函数,我们需要生成一个windows通用函数哈希列表。想要做到这点,我们只需要获取一个windows通用库的列表,然后遍历这些库的函数列表。代码如下:
#!python
def get_functions(dll_path):
pe = pefile.PE(dll_path)
if ((not hasattr(pe, 'DIRECTORY_ENTRY_EXPORT')) or (pe.DIRECTORY_ENTRY_EXPORT is None)):
print "[*] No exports for %s" % dll_path
return []
else:
expname = []
for exp in pe.DIRECTORY_ENTRY_EXPORT.symbols:
if exp.name:
expname.append(exp.name)
return expname
我们随后可以得到函数名字的列表,然后计算他们的CRC32的哈希值。代码如下:
#!python
def calc_crc32(string):
return int(binascii.crc32(string) & 0xFFFFFFFF)
最后我们将结果写入一个JSON格式的文件中,并且命名为”output.json”。这个JSON文件包含了一个非常大的字典,采用如下的格式:
#!bash
HASH => NAME
完整版的代码如下:
https://github.com/pan-unit42/public_tools/blob/master/ida_scripts/gen_function_json.py
当这个文件生成之后,我们可以返回IDA,并且继续编写我们的IDAPython脚本。我们脚本第一步要做的事情是读取我们之前创建的’output.json’这个JOSON数据文件。不幸的是,JSON对象并不支持整数作为key,因此当数据被加载后,我们需要手动把key从字符串转换为整数。代码如下:
#!python
for k,v in json_data.iteritems():
json_data[int(k)] = json_data.pop(k)
当这些数据被加载后,我们将会创建一个枚举对象保存了哈希值与函数名的对应关系。(想要了解更多的关于枚举对象的信息,我推荐你阅读这篇教程:
http://www.cprogramming.com/tutorial/enum.html
使用枚举对象,我们可以找到一个整数对应的字符串,比如说CRC32哈希值对应的函数名。为了在IDA中创建新的枚举对象,我们可以使用AddEnum()这个函数。为了让这个脚本更加健壮,我们先使用GetEnum()函数来检测用来枚举的值是否已经存在。
#!python
enumeration = GetEnum("crc32_functions")
if enumeration == 0xFFFFFFFF:
enumeration = AddEnum(0, "crc32_functions", idaapi.hexflag())
这个枚举的值随后将会被修改。下一步要干的事情是根据函数的哈希值来确定真实的函数地址。这一部分看起来很像第一部分的内容。我们通过观察这个函数的结构可以发现CRC32哈希值是这个加载函数的第二个参数。
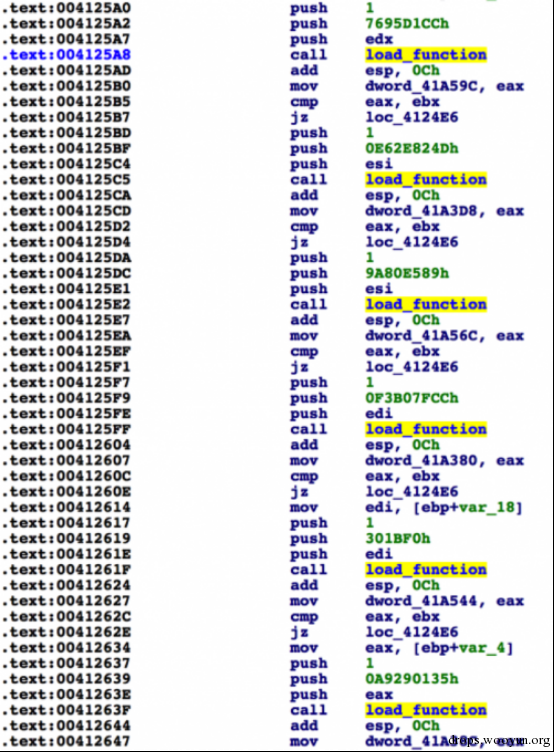
 图片8 传递给load_function()的参数
图片8 传递给load_function()的参数
同样的,我们还是枚举之前的指令来寻找函数的第二个参数。当我们找到后,我们通过output.json中的JSON数据来进行检测,并且确保有一个函数名对应了这个哈希值。代码如下:
#!python
for x in XrefsTo(load_function_address, flags=0):
current_address = x.frm
addr_minus_20 = current_address-20
push_count = 0
while current_address >= addr_minus_20:
current_address = PrevHead(current_address)
if GetMnem(current_address) == "push":
push_count += 1
data = GetOperandValue(current_address, 0)
if push_count == 2:
if data in json_data:
name = json_data[data]
这个时候,我们使用AddConstEx()这个函数将CRC32哈希和函数名加入我们之前创建的枚举对象中。
#!python
AddConstEx(enumeration, str(name), int(data), -1)
当这个数据加入到枚举对象中后,我们可以将CRC32的哈希值转换为对应的枚举名字了。下面的两个函数一个是用来将一个整数转换成对应的枚举数据,另一个是用来将某个地址的数据转换成对应的枚举数据。
#!python
def get_enum(constant):
all_enums = GetEnumQty()
for i in range(0, all_enums):
enum_id = GetnEnum(i)
enum_constant = GetFirstConst(enum_id, -1)
name = GetConstName(GetConstEx(enum_id, enum_constant, 0, -1))
if int(enum_constant) == constant: return [name, enum_id]
while True:
enum_constant = GetNextConst(enum_id, enum_constant, -1)
name = GetConstName(GetConstEx(enum_id, enum_constant, 0, -1))
if enum_constant == 0xFFFFFFFF:
break
if int(enum_constant) == constant: return [name, enum_id]
return None
def convert_offset_to_enum(addr):
constant = GetOperandValue(addr, 0)
enum_data = get_enum(constant)
if enum_data:
name, enum_id = enum_data
OpEnumEx(addr, 0, enum_id, 0)
return True
else:
return False
当我们把这个枚举转换完成后,我们来研究一下如何修改DWORD处的值,因为DWORD处的值保存了加载后的函数地址。
 图片9 当加载完函数后,程序将函数地址存储到了DWORD地址
图片9 当加载完函数后,程序将函数地址存储到了DWORD地址
为了做到这一点,我们不光需要遍历之前的指令,还要查找之后的指令,也就是将eax存储到一个DWORD地址的指令。当我们发现这条指令之后,我们可以给这个DWORD地址重新命名成正确的函数名。为了防止冲突,我们在函数名前加上一个”d_”字符串。
#!python
address = current_address
while address <= address_plus_30:
address = NextHead(address)
if GetMnem(address) == "mov":
if 'dword' in GetOpnd(address, 0) and 'eax' in GetOpnd(address, 1):
operand_value = GetOperandValue(address, 0)
MakeName(operand_value, str("d_"+name))
等这一切都做完后,我们会发现原来很难读懂的汇编代码变得很好理解了。如图所示:
 图片10 运行完脚本后的变化
图片10 运行完脚本后的变化
现在,当我们看到DOWRDS列表的时候,就已经能得到真实的函数名字了。并且这些数据能够很好的帮助我们进行静态分析。

完整的代码如下:
#!python
import json
def get_enum(constant):
all_enums = GetEnumQty()
for i in range(0, all_enums):
enum_id = GetnEnum(i)
enum_constant = GetFirstConst(enum_id, -1)
name = GetConstName(GetConstEx(enum_id, enum_constant, 0, -1))
if int(enum_constant) == constant: return [name, enum_id]
while True:
enum_constant = GetNextConst(enum_id, enum_constant, -1)
name = GetConstName(GetConstEx(enum_id, enum_constant, 0, -1))
if enum_constant == 0xFFFFFFFF:
break
if int(enum_constant) == constant: return [name, enum_id]
return None
def convert_offset_to_enum(addr):
constant = GetOperandValue(addr, 0)
enum_data = get_enum(constant)
if enum_data:
name, enum_id = enum_data
OpEnumEx(addr, 0, enum_id, 0)
return True
else:
return False
def enum_for_xrefs(load_function_address, json_data, enumeration):
for x in XrefsTo(load_function_address, flags=0):
current_address = x.frm
addr_minus_20 = current_address-20
push_count = 0
while current_address >= addr_minus_20:
current_address = PrevHead(current_address)
if GetMnem(current_address) == "push":
push_count += 1
data = GetOperandValue(current_address, 0)
if push_count == 2:
if data in json_data:
name = json_data[data]
AddConstEx(enumeration, str(name), int(data), -1)
if convert_offset_to_enum(current_address):
print "[+] Converted 0x%x to %s enumeration" % (current_address, name)
address_plus_30 = current_address+30
address = current_address
while address <= address_plus_30:
address = NextHead(address)
if GetMnem(address) == "mov":
if 'dword' in GetOpnd(address, 0) and 'eax' in GetOpnd(address, 1):
operand_value = GetOperandValue(address, 0)
MakeName(operand_value, str("d_"+name))
fh = open("output.json", 'rb')
d = fh.read()
json_data = json.loads(d)
fh.close()
# JSON objects don't allow using integers as dict keys. Little workaround for
# this issue.
for k,v in json_data.iteritems():
json_data[int(k)] = json_data.pop(k)
conversion_function = 0x00405680
enumeration = GetEnum("crc32_functions")
if enumeration == 0xFFFFFFFF:
enumeration = AddEnum(0, "crc32_functions", idaapi.hexflag())
enum_for_xrefs(conversion_function, json_data, enumeration)
0x04 总结
在上一节中,我们利用IDAPython成功的解决了一个哈希混淆的问题,在这个问题中我们用到了枚举对象。枚举对象对我们分析这类问题会很有帮助,能够节省我们大量的时间。并且这个对象可以很容易的在IDA工程中提取或者加载,这对我们进行批量的逆向分析会很有帮助。









 - MalwareBenchmark")







 云悉指纹
云悉指纹