0x01 写在前面
这篇文章主要是为了分享和记录自己的一些成长,如有写得不好的地方,还望斧正。在最早期针对漏洞管理这个事情,个人觉得比较恶心。特别是各种邮件发来发去,到最后追溯到某个系统曾经出现的安全风险时,一顿猛翻,甚至连源邮件出处都找不到…然后就有了这篇文章。
0x02 原来的方式
原来的方式比较蛋疼的是,这里面有很多各种各样的问题,各种各样的拖延,例如:研发会质问,这个漏洞严重吗,为啥要马上修复?又比如:这个漏洞是正常逻辑,需要修改还要过产品那边,又或者这个漏洞看不懂啥的,又比如你提供的信息不够全面等等。因为这些问题导致修复一个漏洞需要2-3天,甚至更长的时间。
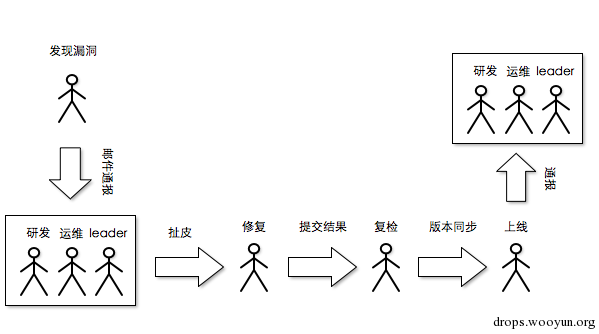
然而对于我们来说,这是0容忍的。所以我们需要推动,浪费很多口水跟这些人解释,如果title比较高的情况下,可能比较好操作,如果只是最基层,可能就….而且还有一个问题,不知道其他的小伙伴有没有遇到过,就是突然某天你所管辖的系统被人爆了,然后莫名其妙的可能存在很多未知的风险,再然后就是领导找你谈话,问你这个系统曾经出现过哪些风险,还有记录么?….然后,你就说,都有邮件…然后领导说:你搞下,把这些东西整理出来…然后:xx^&*($%^&
0x03 改善
在发现这个问题以后,我试图改变这个现状,从沟通需求开始、去咨询研发、还有我们需要服务的部门,到底怎样做才能做到最好。逐步,我开始设计一个自动化的方式来提高整体的效率,包括流程的问题。我初步认为,这个流程不需要太复杂,并且我认为这个跟快递管理的理念是一致的『使命必达』。说干就干,梳理下我认为比较达标的方式:
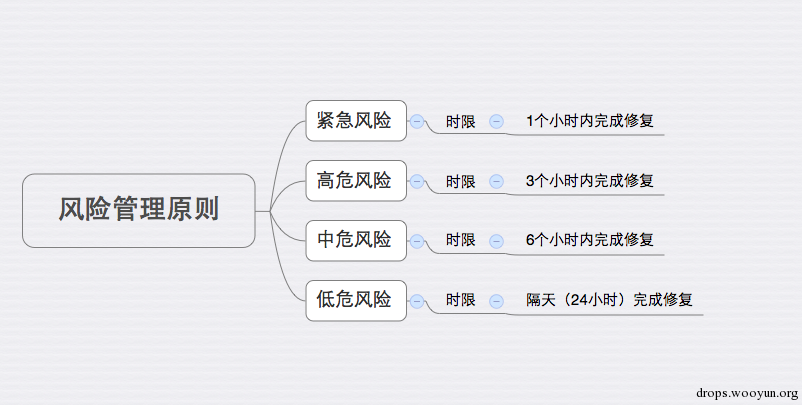
想到达到这个目标不是一般的难,起码中间扯皮是比较麻烦的事情,但是如果我们能把这个东西做出来,也是一种成就。
0x04 撸成代码
既然我们知道了目标就可以开始试图模拟这种场景来实现这个效果。当然,前题你需要得到上面的支持,非常荣幸,在坚持自己见解后,得到了最大力度的支持。
我的设计如下:
-
发现漏洞,上报漏洞(通过安全平台发起=>研发收到该漏洞信息邮件)他可以通过登录平台查看详细信息,或者通过邮件了解该漏洞的细节。在确认知悉后,点击『已知悉』会通过该方式对安全平台的API进行一次请求,并且更新当前该漏洞的处理状态。(安全提交=>平台发送=>研发收)
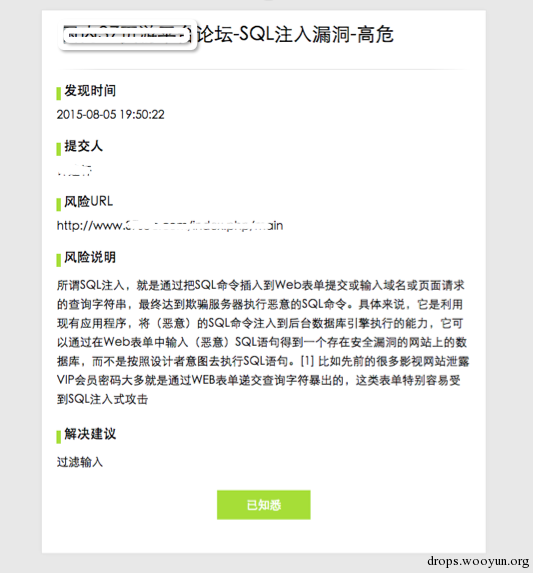
-
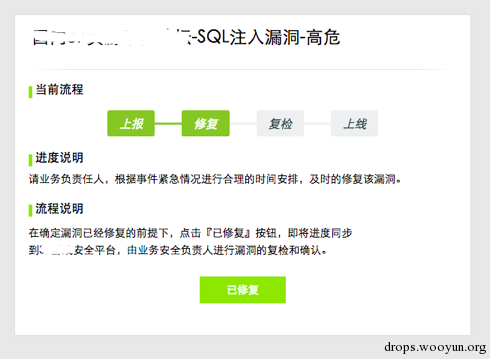
在点击『已知悉』后,研发再次收到平台发起的一个电子流,提示该漏洞执行中的流程,在修复完成后,研发再次进行下一步操作。(平台发=>研发收)
-
在确认漏洞已修复的时候,通过点击『已修复』进入漏洞的复检流程。(平台发=>研发收)

-
在确认漏洞已经修复完成后,安全人员针对漏洞进行复查,灰度测试环境上线。(平台发=>安全收)在这里,安全人员有两个选择,一个是『确认修复』、一个是『漏洞打回』由于有的时候漏洞有可能修复不全面,导致可以二次利用。所以有可能漏洞会被打回。(平台发=>安全收)

-
在漏洞测试完成后后,研发或运维会根据实际情况,对代码进行完整的同步。在全部完成后,点击『已同步环境』则漏洞修复流程结束。(平台发=>研发/运维收)
整个过程通过电子流的方式实现,同样使用了邮件的方式,但是可以明显看出来整个漏洞的处理过程非常清晰、直观。同时,妈妈再也不担心漏洞的历史无法追溯了。有了数据,随时可查。可视化管理~
展示下平台的漏洞管理是啥样的。
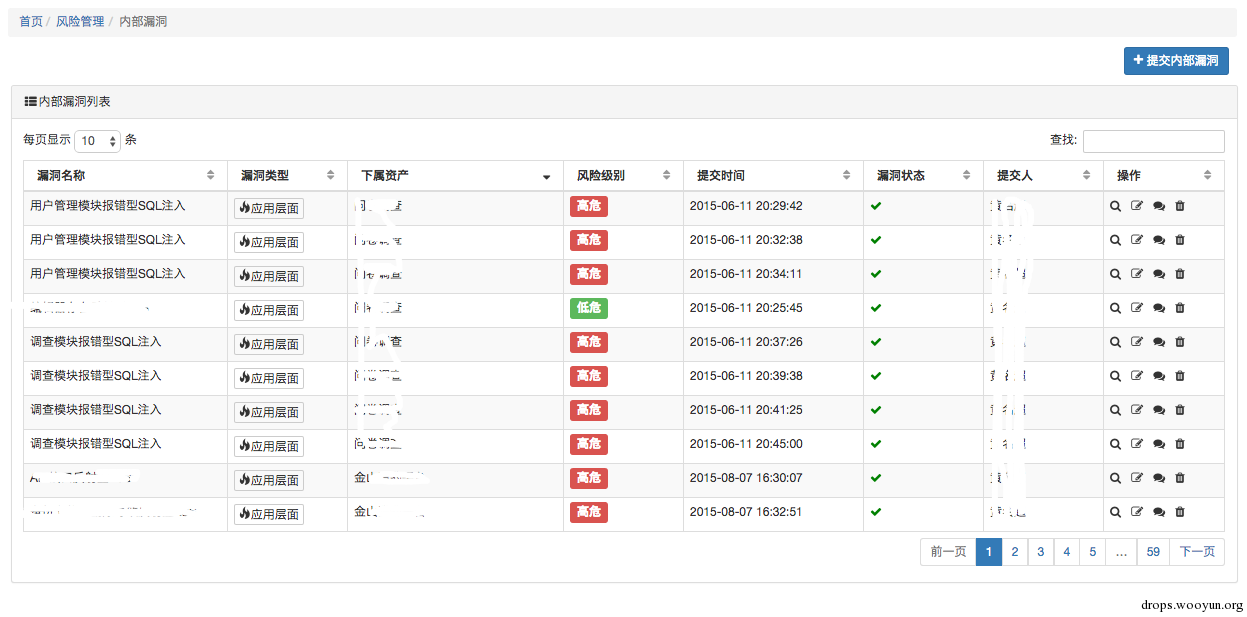
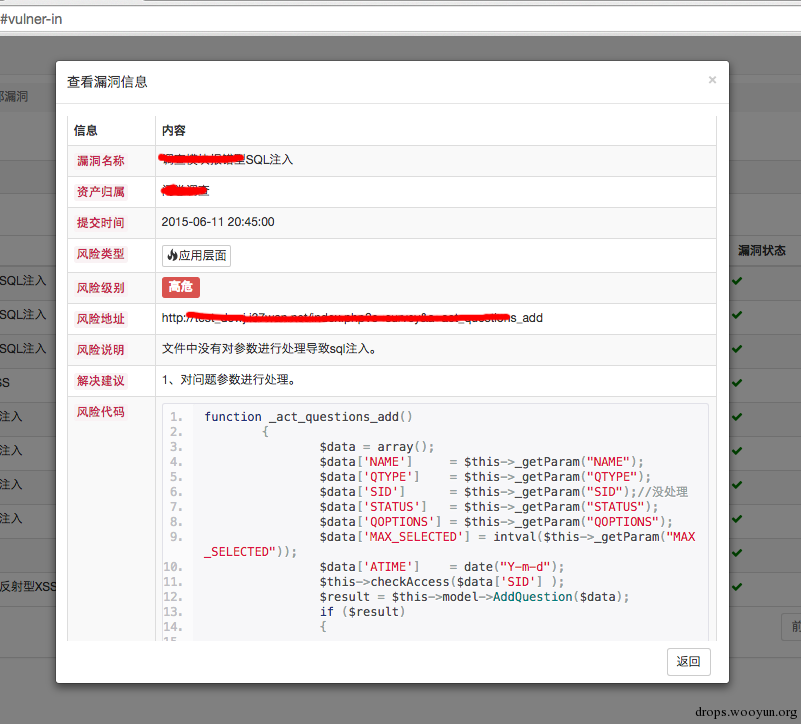
0x05 需要注意
- token的时效问题:首先,你是通过邮件的方式发出、发入,势必会有时效的问题产出,你需要将token设置在合理的范围时间,这个根据你的实际情况来定,我预设的是在1天内token有效。
- 风险描述问题:以上的描述和实际使用的版本有些不同,毕竟有保密的需求,这个东西需要你跟研发、运维、还有你们自己的大哥沟通清楚,了解清楚怎么做才是最合理的。
- 在风险处理时间上,在系统上最好做个关联,例如该类风险超过一定时间没有修复,提前多久给研发发提醒,毕竟有的时候可能会忘记,最好就是有一定的提醒功能,这样会更加友好。(我还是挺关注用户体验的)
0x06 送个漫画








![Cobalt Strike安装使用教程与DNS通讯演示[转]](https://www.vuln.cn/wp-content/uploads/2015/09/2014071404364042830.jpeg)

")






 云悉指纹
云悉指纹