0x00 前言
项目开源地址: https://github.com/manning23/MSpider
上篇文章《爬虫技术浅析》介绍了爬虫的基本技术,分享了一个动态爬虫demo。这篇文章主要讲解爬虫技术的实战效果。 本次介绍的结果如下:
-
1.爬虫的URL聚焦与过滤
-
2.URL相似度算法抛砖引玉
-
3.爬行策略详解
-
4.Mspider工具使用说明及效果展示
-
5.Mspider的头脑风暴
0x01 爬虫的URL聚焦与过滤
为什么爬虫需要URL聚焦与过滤?因为我们需要控制预期结果!
举个例子,如果爬行的目的是爬取乌云已知漏洞列表,那么一般类型的爬虫是无法满足的,一般爬虫会进行如下形式的爬取。爬取的URL是杂乱的。
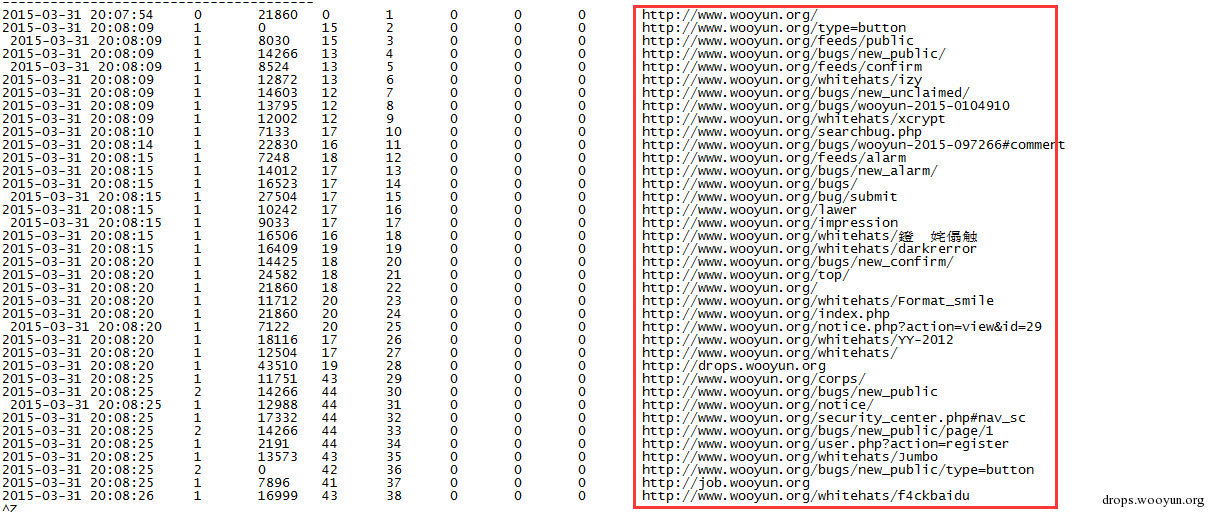
聚焦爬虫爬取的URL是符合预期的。如下图展示。
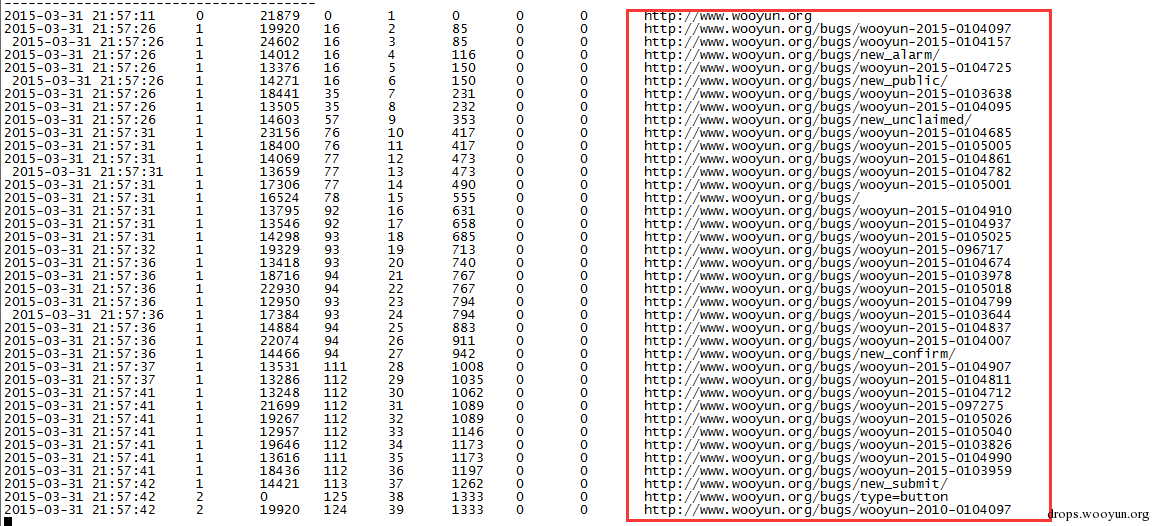
可以看出来,聚焦爬虫和非聚焦爬虫都是从www.wooyun.org开始爬取,聚焦爬虫可以按照一定策略尽量控制URL爬取策略,而非聚焦爬虫却完成不了这种特定需求。
在爬虫过滤模块中,我们需要理解什么是过滤,什么是聚焦。简单的说,如果过滤关键字在url中,则返回False,否则返回True。如果聚焦关键字在url中,则返回True,否则返回False。具体可以查看Mspider中的urlfilter.py文件。
0x02 URL相似度算法抛砖引玉
URL相似度算法在爬虫里不言而喻,这个算法直接决定着爬虫的爬行效率,我将讲解一下我的算法,算是抛砖引玉。
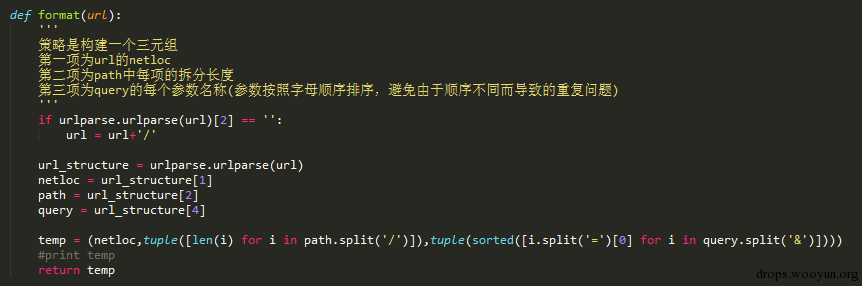
这个算法主要是依靠对URL的拆解与对拆解对象的HASH,这个算法适用类似的需求常见。这个算法是将一个URL拆解为三个维度,第一个维度是netloc,第二个维度是path的各项长度,第三个维度是query对象的参数排序后列表。通过一个数据结构对以上三个维度组合,构建一个可hash的对象。
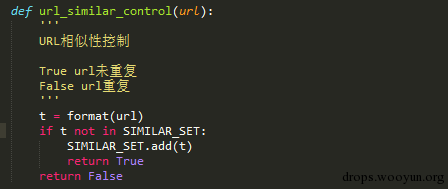
利用集合数据结构进行去重,这个能大幅减小普通URL相似度算法对于hash后结果冲突的问题。实际效果如下图。
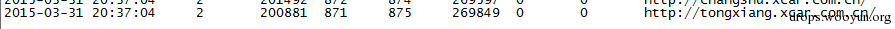
当爬取了875个链接时,实际相似页面已达到了269849个,因此对于爬虫效率来讲,是个很好的提升。
这个算法只是实际经验值,实践后得到良好的实际效果,希望大家也能思考更为优秀的相似度算法。
0x03 爬行策略详解
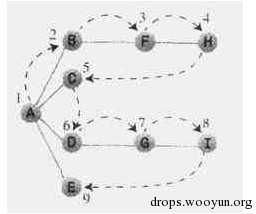
一般爬行策略为广度优先、深度优先。深度优先搜索通过栈来实现,而广度优先搜索通过队列来实现。
下面图中的数字显示了深度优先搜索顶点被访问的顺序。
下面图中的数字显示了广度优先搜索顶点被访问的顺序。
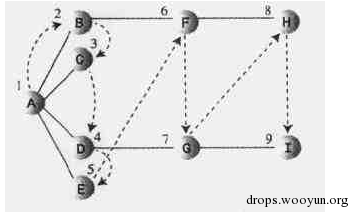
Mspider中实现爬行策略,这三种搜索方式都是通过对URL队列的排序方式进行调整,通过队列中URL结点的深度参数进行调整,来达到需求目的,爬行策略根据不同需求设置,能更快的发现可疑URL链接。
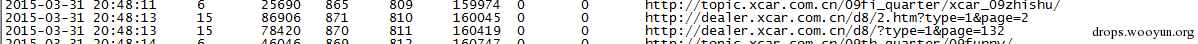
上图当爬行了810个链接时,实际爬行的深度已达到了15层。在实际测试过程中,深度优先爬行能更好的发现可疑链接。
0x04 Mspider工具使用说明及效果展示
Mspider是本人开发的一个以CLI方式运行的爬虫工具。此爬虫实现了如下功能。希望大家多多star和fork。也欢迎大家随时给我邮箱发送邮件提bug。
CLI下展示如下:
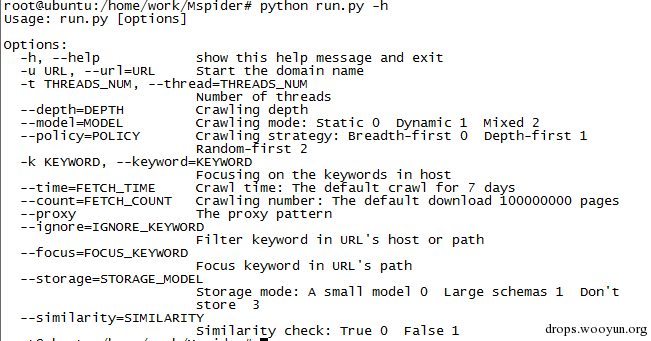
此爬虫还可以通过文件的config.py进行更详细的配置,比如爬行间隔,忽略标签列表,动静分配比例,user-agent字典等。
提供几个测试场景:
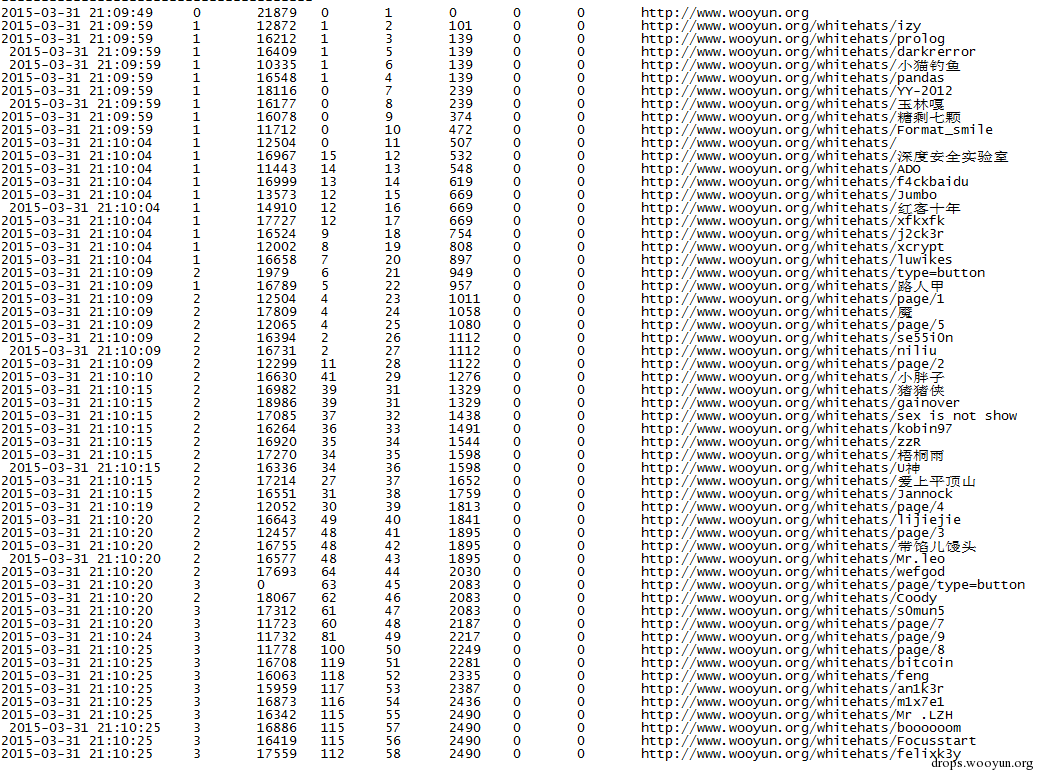
爬行乌云白帽子列表
命令:
#!bash
python run.py -u "http://www.wooyun.org" -k "wooyun.org" --focus "whitehats" --similarity 1 --storage 3
效果:
深度优先爬行edu站点,进行url相似度过滤,爬行个数为500个
命令:
#!bash
python -u run.py "http://www.njtu.edu.cn/" -k "edu.cn" --policy 1 --storage 0 --count 500
效果:

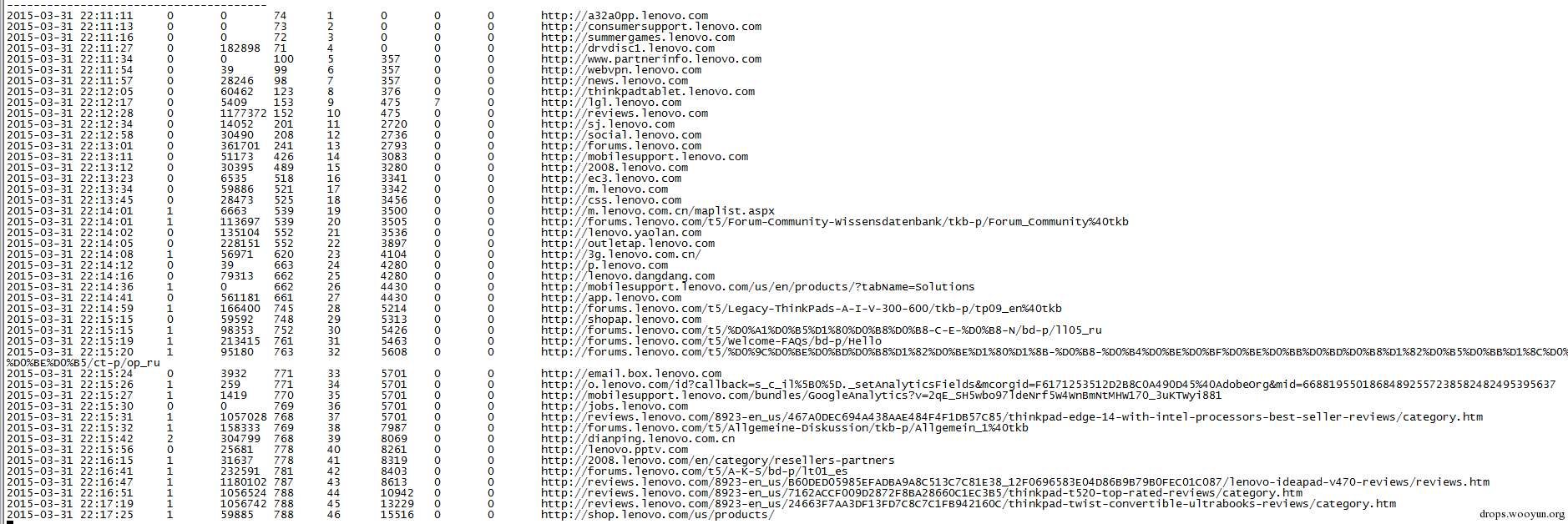
爬行联想域名内连接,域名过滤bbs关键字,动态爬行网页,随机优先策略
命令:
#!bash
python run.py -u "lenovo" -k "lenovo" --ignore "bbs" --model 1 --policy 2
效果:
0x05 Mspider的头脑风暴
通过改写Mspider的一些功能,比如页面分析模块,URL过滤模块,数据储存模块,可以获得更深入更有意思的信息。
举个例子,想要获取乌云中sql注入类型漏洞的SQL注入payload。在聚焦爬虫中,通过对改写数据储存模块,让数据库记录获取的dom树,并储存,接着对dom树进行数据挖掘,便可简单实现。









 - 夸父追日")
 - blast")






 云悉指纹
云悉指纹