这个问题困扰了我估计有一个星期问题,而问题的一开始我没有任何头绪,问题的表现就是调用节点去请求任务时,时常报错:
报错信息诸如:
Protocol Error: , b'\x00\x00\x00\x00\x00\x00\x00\x00\x00*3'
Error while reading from socket: (9, 'Bad file descriptor')
'int' object has no attribute 'decode'
name 'self' is not defined
only (P)SUBSCRIBE / (P)UNSUBSCRIBE / PING / QUIT allowed in this context
Protocol Error: ", b'status": "SUCCESS", "result": false, "traceback": null, "children": [], "task_id": "1cbba409-b48a-49a6-b2e3-a5d6d203fc6d"}'
我的celery backend 为redis,一开始,我的排错心酸历程如下:
1.可能是redis所在的服务器出口网速不足,导致客户端从redis取数据延迟,于是调增了系统tcp最大并发数
2.可能是节点服务器性能与网速不足,导致结果写入redis有延迟或错误
于是我花了2000多升级了带宽与内存,发现然并卵
3.可能是线程锁的问题,然并卵
4.请求的网址越慢出错率越高,让我深信为延迟导致。
5.可能是redis中存储的数据格式字节数太多,于是修改“yaml”
app = Celery('finger_module_celery', broker=brokers, backend=backend,task_serializer='yaml')6.去redis里看了下,存储的结果并没有问题,所以还是从redis取数据过程出现了问题,
于是我打印详细点:
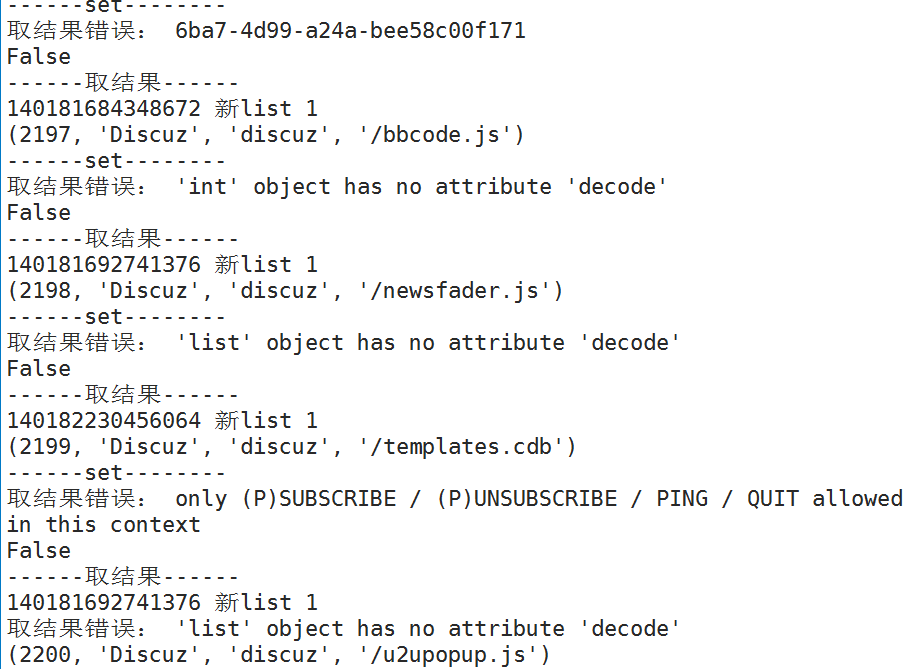
基本上判定,只要取结果出现了错误,推送任务就会出错,并且很多时候单线程也会出错。
处于对celery的信任,我没有怀疑celery中get()方法有问题。
前几天想了下,是不是该用个笨方法:把取数据时间延迟一点,确保能取到数据,处于对技术的完美追求,觉得这个方法有点侮辱自己的代码,没有试,昨天晚上还是决定尝试一下。
代码如下:
def Celery_get(function,list,queue):
'''
:param function: 分布式需要推送的函数
:param list: 函数的args
:param queue: celery服务端中的任务队列
:return: 节点处理完的数据
'''
time = 0.1
try:
res = function.apply_async(args=list, queue=queue)
except Exception as e:
print('推送任务错误:', list, e)
return False
try:
while True:
if res.ready():
return res.get()
else:
sleep(time)
except Exception as e:
print('取结果错误:',e)
return False单独定义一个推送任务与取结果的函数,用延时来让直到ready()为真时才取结果,如果不行再延迟。
经过测试发现,貌似就差这么0.1秒,完美运行无瑕疵,没有再报错。
2018年12月12日 更新
今天偶然发现文章开头提到的报错,在部分情况下也是会受带宽影响。
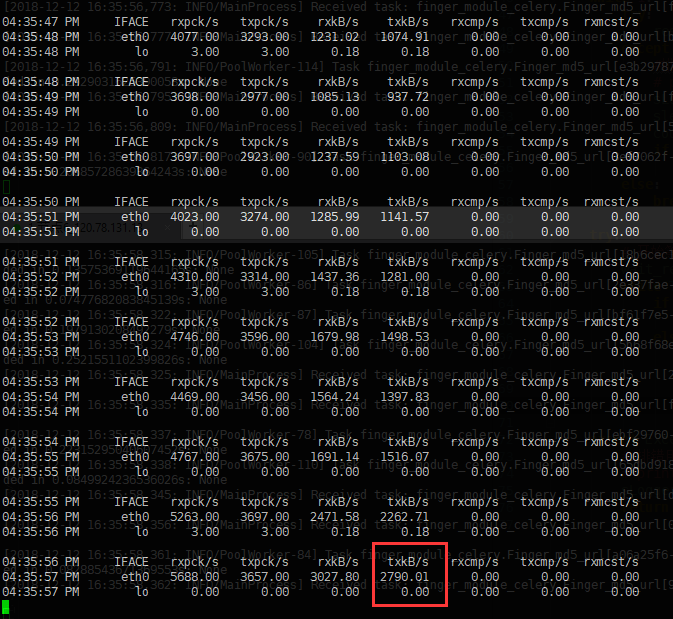
如果任务量比较大,分布式节点使用外网链接,一定要观察rabbitmq 服务器的带宽使用情况,是否已经达到了出口带宽瓶颈
如下图:3M左右出口带宽的机器,在celery使用外网的时候,txkb/s 维持在800多,已经达到了瓶颈;在修改成内网链接后 网络吞吐达到2790多txkb/s,报错也少了很多,但还会有,所以带宽问题虽然不是根本问题,但也是可以优化的一个维度。

与task_done()的关系")
")


















 云悉指纹
云悉指纹