爬取js的必要性在这里就不必多说了,也就是直接请求html并不会返回js所加载的数据,只有经过浏览器渲染后才回出现数据,比如在http://s.tool.chinaz.com/same 查询出的数据是经过js加载的(一方面为了数据不会被搜索引擎爬取,另一方面降低服务器并发负载)。 这种情况python一般可以用PhantomJS实现,这个工具也是在爬虫界最受好评的一个工具,而且它并不是python模块。
selenium+PhantomJS下载安装
selenium安装方法:
直接pip install selenium即可
PhantomJS下载安装:
官网:http://phantomjs.org/ 官网的下载超慢,我传到了网盘:http://pan.baidu.com/s/1nvhU577 下载解压,直接将“phantomjs.exe” 文件放到一个固定位置,用来被调用即可 下面直接来一个我写的例子,站长工具查询博客的同ip网站
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
import time
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
params = DesiredCapabilities.PHANTOMJS #这本身是一个dict格式类属性
params['phantomjs.page.settings.userAgent'] = ("Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/53 "
"(KHTML, like Gecko) Chrome/15.0.87") #在这个类属性里加上一个“phantomjs.page.settings.userAgent”
driver = webdriver.PhantomJS(executable_path=r'D:\Python34\phantomjs-2.1.1-windows\bin\phantomjs.exe',desired_capabilities=params)
print(params) #打印下这个属性看看还有那些参数
driver.get('http://s.tool.chinaz.com/same?s=www.vuln.cn&page=1') #这时候get方法请求的时候调用DesiredCapabilities.PHANTOMJS属性的时候就会用上指定的header
time.sleep(2)
content = driver.page_source
soup = BeautifulSoup(content)
for x in soup.find_all('div', class_='w60-0 tl pl10'):
print(x.contents[0])
返回: 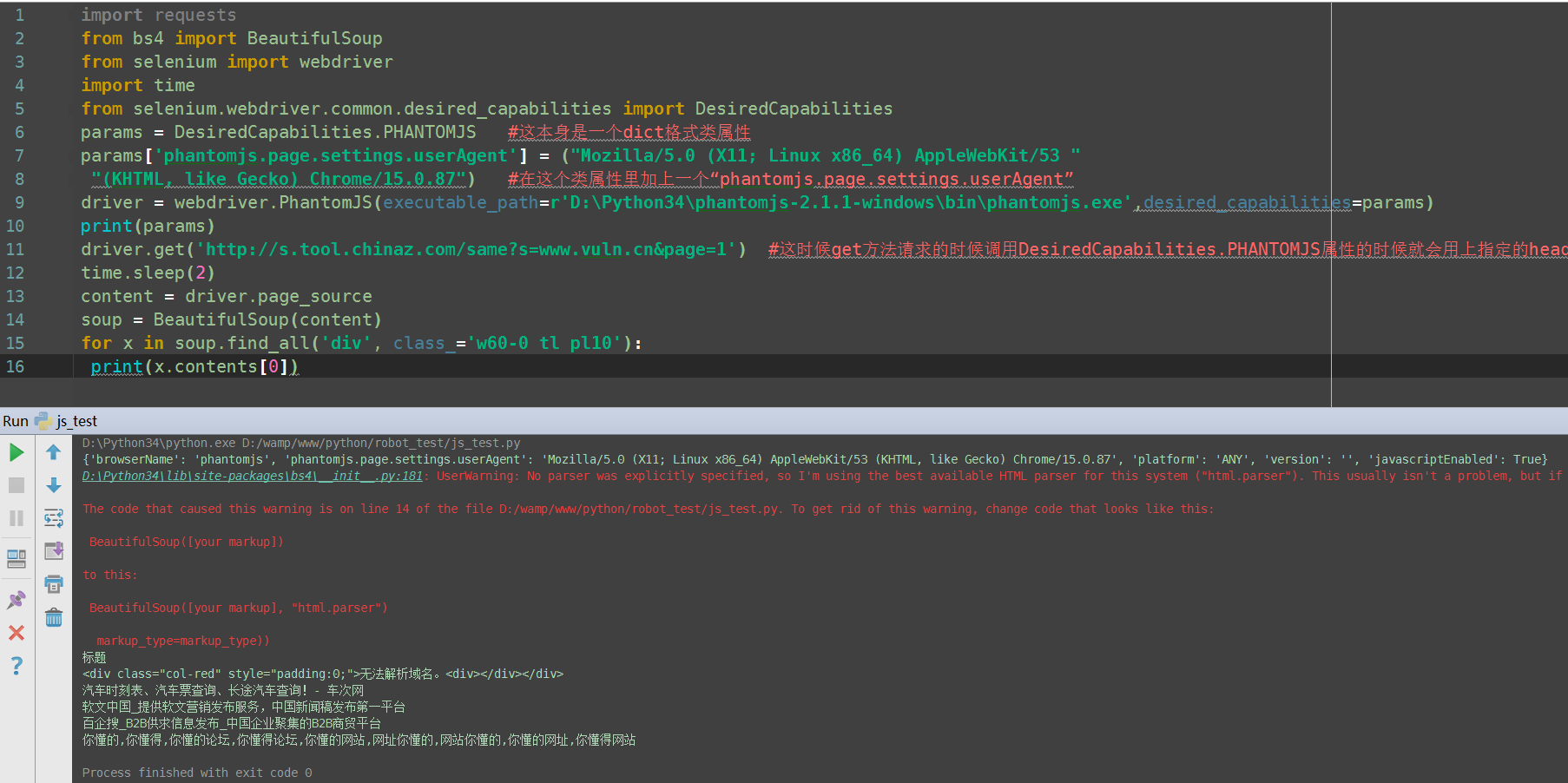 可以看到在这个dict中我们加的user-agent 实际的请求头user-agent也确实是我们改过的,大家可以自己尝试
可以看到在这个dict中我们加的user-agent 实际的请求头user-agent也确实是我们改过的,大家可以自己尝试
![Python selenium+PhantomJS实现爬取动态JS[自定义header]](https://www.vuln.cn/wp-content/themes/wpgo/caches/7a8d42599a88d7fef1ef8ea9da9c8f02.jpg "扫一扫本文二维码,分享给大家")












栈溢出漏洞调试笔记 - Debug_Orz")






 云悉指纹
云悉指纹