以下为我毕业设计的部分内容的第二章,“搜索引擎的工作原理”,第一章是引言,那就不用放上来了,因为是论文,所以写的有点文邹邹的…………
2 搜索引擎的工作原理
2.1 搜索引擎爬虫
对于爬虫不同的搜索引擎又不同的俗称,比如百度的爬虫称之为“百度蜘蛛(baiduspider)”,google称之为“爬虫(googlebot)”。爬虫的作用:互联网上目前有数以百亿计的网页,爬虫首选需要做的就是,将如此海量的网页数据下载到服务器本地,本地形成互联网页面的镜像备份。传送到本地后,再经过后续的一些算法流程处理这些页面,将之呈现在搜索结果上。
2.1.1 搜索引擎爬虫框架
一般的爬虫框架流程为:从互联网海量页面中先抓取一些高质量页面,抽取其中所包含的url,将这些URL放入待抓取队列中,爬虫依次读取该队列中的url,通过DNS解析,将这些url转化成对应网站的IP地址,网页下载器则通过IP地址下载页面所有内容。
对于已下载到本地服务器的页面,一方面等待建立索引以及后续处理;另一方面将这些已下载的页面记录下来,以免再次被抓取。
对于刚下载的页面,从页面中抓取页面中所包含未被抓取的URL,放到待抓取队列中,后续抓取过程中将下载该URL对应的页面内容,如此循环,知道待抓取队列为空,则完成一轮抓取 。如图所示:
图2-1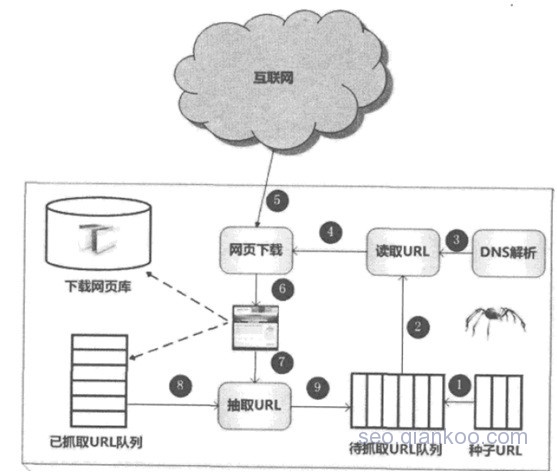
当然,在如今互联网信息不断海量的时代,为了保证效率,爬虫一般会持续不断的工作。
所以,由此从宏观上我们可以了解,互联网的页面可以划分为以下5各部分:
a) 已下载页面集合
b) 已过期页面集合
c) 待下载页面集合
d) 可知的页面集合
e) 不可知的页面集合
当然,为了确保页面质量,在以上的一个爬虫抓取过程中还涉及了很多技术手段。
2.1.2 搜索引擎爬虫的分类
绝大多数的搜索引擎爬虫系统都是按照上述的流程来工作的,但是不同的搜索引擎的爬虫会有所区别,另外同一个搜索引擎的爬虫还有多种分类。按照功能分类:
a) 批量型爬虫
b) 增强型爬虫
c) 垂直型爬虫
百度搜索引擎按照产品分类为:
a) 网页搜索Baiduspider
b) 无线搜索Baiduspider-mobile
c) 图片搜索Baiduspider-image
d) 视频搜索Baiduspider-video
e) 新闻搜索Baiduspider-news
f) 百度搜藏Baiduspider-favo
g) 百度联盟Baiduspider-cpro
h) 移动搜索baidu+Transcoder
2.1.3 搜索引擎爬虫的特性
由于互联网信息繁多,且数据巨大,搜索引擎必须有优秀的爬虫才能完成高效率的爬取流程。
a) 高性能
搜索引擎的爬虫高性能主要体现在单位时间内能够下载多少网页,互联网的网页数量浩瀚如海,那么网页的下载速度与工作效率直接相关,另外程序访问磁盘的操作方式也至关重要,所以高性能的数据结构对于爬虫的性能影响也很大。
b) 健壮性
因为蜘蛛需要爬取的互联网页面数量很庞大,虽然下载随度很快,但是仍然需要很长的周期才能完成一个抓取流程,所以蜘蛛系统需要有能力灵活的通过增加服务器的数量和爬虫数量来提高小效率。
c) 友好性
爬虫的友好性主要体现在两个方面,
一方面是需要顾及网站服务器的的网络负载,因为不同的服务器的性能与承载能力不同,而如果蜘蛛爬取的压力过大,造成类似DDOS攻击的效果,可能会影响该网站的访问,所以蜘蛛在互联网爬取的时候需要注重网站负载。
另一方面就是需要保护网站的隐私,因为并不是互联网上的所有页面都是允许搜索引擎蜘蛛去爬取和收录的,因为这个页面别人不希望被搜索引擎收录,从而能别被别人从网上搜索到。
而限制蜘蛛的爬取一般有三种方式:
1) 爬虫禁抓协议(robot exclusion protocol)
网站所有者在网站的根目录制定一个robots.txt文件,该文件中说明了该网站中有哪些目录与页面是不允许百度蜘蛛爬取的
一般的robots.txt文件格式如下:
User-agent: baiduspider
Disallow: /wp-admin/
Disallow: /wp-includes/
其中user-agent字段指定针对哪个搜索引擎的爬虫disallow字段指定不被允许爬取的目录或路径。
2) 网页禁抓标记(robot metatag)
在某页面的head头部添加网页禁抓标记达到禁止收录该页面的作用。有两种形式:
<meta name=”robots”content=”noindex”>
此形式告知不允许搜索引擎爬虫索引该页面的内容。
<meta name=”robots”content=”nofllow”>
此形式告知爬虫不允许抓取该页面所包含的所有链接
2.1.4 爬虫的抓取策略
在整个爬虫系统中,待抓取队列是核心,所以如何确定待抓取队列中的URL顺序是至关重要的,除了在之前所提到,将新下载的页面中所包含的URL自动追加到队列尾部的技术外,很多情况下需要运用到其他技术来判定待抓取队列中的URL排列顺序,而所有的抓取策略,其基本目标都是一致的:优先抓取重要的网页。
常见的爬虫抓取策略有:宽度优先遍历策略、非完全pagerank策略、OPIC策略及大站优先策略。
2.1.5 网页更新策略
该算法的意义在于:互联网上页面多,更新快,所以当互联网上的一个页面内容更新后,爬虫需要及时的去重新爬取该页面,经过索引,重新展示给用户,否则容易出现用户在搜索引擎搜索结果列表中看到的结果与实际页面内容不一致的情况。常见的更新策略有三种:历史参考策略,用户体验策略,聚类抽样策略。
a) 历史参考策略
历史参考策略很大程度上依靠的是一个网页历史的更新频率,从历史更新频率判断一个页面的未来更新时间,从而指导爬虫的工作。更新策略还依据一个页面的更新区域来判断内容的更新,比如一个网站的导航与底部等一般是不会变动的。
b) 用户体验策略
顾名思义,该更新策略与用户体验数据直接相关,即,认为一个页面如果不太重要的话,那么迟点更新也是关系不大的,那么如何判断一个页面的重要性呢?因为搜索引擎的爬虫系统与排名系统是相对独立的,所以,当一个页面的质量变化的时候,那么他的用户体验数据会随之变化,从而导致排名随之变化,从此判断一个页面的质量的变化,即,对用户体验影响越大的页面,更新则应越快。
c) 聚类抽样策略
以上介绍的两种更新策略有很多的局限性,为互联网的每个网页都保存其历史页面的成本是巨大的,另外,首次抓到的页面是没有历史数据的,所以也就无从判定更新周期,所以聚类抽样的策略很好的解决了以上两种策略的弊端。即:将每个页面根据其属性进行分类,同一类别中的页面具有类似的更新周期,所以,根据页面所在的类别判定其更新周期。
而对于每个分类的更新周期:从各自分类中抽取具有代表性的页面,根据前面两种更新策略,计算其更新周期。
页面属性的分类:动态特征与静态特征。
静态特征一般为:页面内容的特征,比如文字字、大小,图片尺寸、大小,链接深度,pagerank值,页面大小,等等特征。
动态特征即为静态特征随着时间的变化情况,如图片数量的变化,文字多少的变化,页面大小的变化,等等。
聚类抽样策略看似粗糙,以偏概全,但是在实际的应用中,效果是好于前两种策略的。



.jpg "“网站的重要目录对百度进行了封禁”原因分析")
















 云悉指纹
云悉指纹